FastAdaSP is a framework for multitask-adapted efficient inference in large Speech Language Models (SpeechLMs). It incorporates token reduction to optimize memory efficiency, prefilling and decoding speed, providing state-of-the-art results on Dense tasks like Automatic Speech Recognition (ASR) and Speech Translation (ST); Sparse tasks like Emotion Recognition (EM) and Spoken Question Answering (SQA). Unlike other modalities, speech contains unique temporal dependencies that require careful handling, making token reduction more complex. FastAdaSP effectively addresses these challenges by employing a novel weighted token merging strategy that reduces computational costs while maintaining task performance.
With the scaling and advancement of large Speech Language Models like GPT-4o, challenges related to inference latency and memory efficiency remain significant bottlenecks. While many cost-saving techniques for text-only and vision-language models focus on Key-Value (KV) cache compression and token reduction strategies, these methods cannot be directly applied to speech modalities due to the unique characteristics of speech signals.
FastAdaSP uses a weighted token merging technique to reduce redundancy while maintaining essential information. The framework categorizes tasks into two main types: dense tasks (e.g., Automatic Speech Recognition and Speech Translation) where nearly all input audio tokens are essential, and sparse tasks (e.g., Emotion Recognition and Speaker Verification) where only a few tokens contain the crucial information. To accommodate these different task types, FastAdaSP applies specific token reduction methods tailored to each.
For dense tasks, FastAdaSP employs a gradual token merging process to ensure minimal information loss, using strategies such as constant and decay schedules to optimize merging. For sparse tasks, FastAdaSP uses an aggressive token reduction method combined with Transfer Entropy-based layer selection to effectively retain critical information while reducing redundant data. This approach allows FastAdaSP to adapt to different inference requirements without additional training.
The core of FastAdaSP's methodology is a weighted token merge process that calculates similarity scores between adjacent audio tokens and merges them based on these weights. This technique preserves important information while discarding redundant elements, significantly improving memory and computational efficiency. Additionally, FastAdaSP incorporates layer selection mechanisms to ensure that token merging is performed at the most appropriate stages of the model, further optimizing performance.
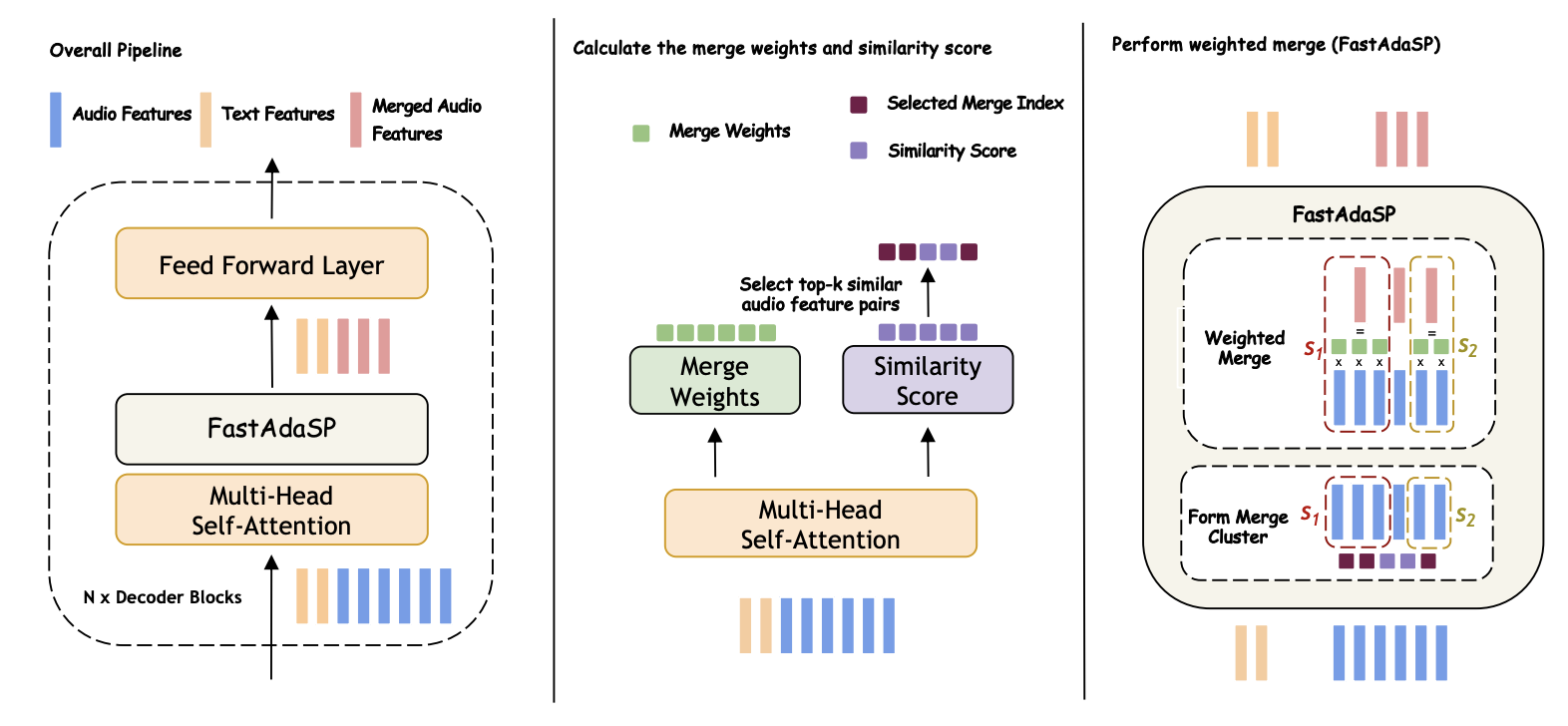
Figure 1: Diagram illustrating the weighted token merge process in FastAdaSP.
Experimental results on WavLLM and Qwen-Audio demonstrate that FastAdaSP achieves significant improvements in both memory efficiency and computational speed. Specifically, FastAdaSP achieved a 7x increase in memory efficiency and a 1.83x increase in decoding throughput compared to baseline methods, without any degradation in task performance.
For dense tasks like Automatic Speech Recognition (ASR), FastAdaSP maintained high accuracy while reducing computational costs by up to 50%. In Speech Translation (ST), the framework effectively balanced the efficiency-performance trade-off, demonstrating only minor degradation in BLEU scores at high reduction levels. For sparse tasks such as Emotion Recognition (ER) and Spoken Question Answer (SQA), FastAdaSP even improved task accuracy by focusing the model's attention on the most informative tokens.
The experiments also highlighted the robustness of FastAdaSP's weighted merge strategy, which outperformed traditional token pruning methods by preserving essential content while reducing redundancy. The use of Transfer Entropy-based layer selection further improved the performance of sparse tasks by ensuring that token reduction occurred at optimal stages, minimizing information loss. Overall, FastAdaSP sets a new benchmark in multitask SpeechLM efficiency, combining state-of-the-art performance with practical applicability across multiple speech-related tasks.
Computational Cost experiments results show that FastAdaSP can also decrease both pre-filling and decoding latency at about 4% and 50% on A100 and H100 GPU.
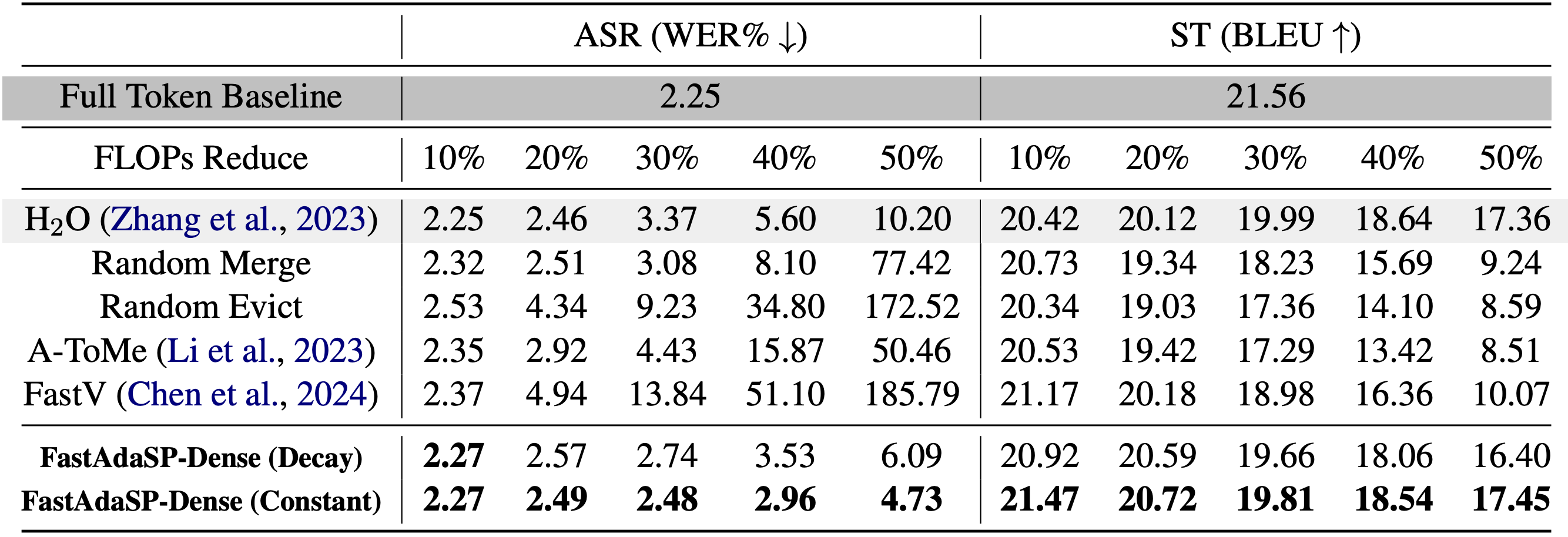
Table 1: Comparison between FastAdaSP with other token reduction methods on WavLLM dense tasks.
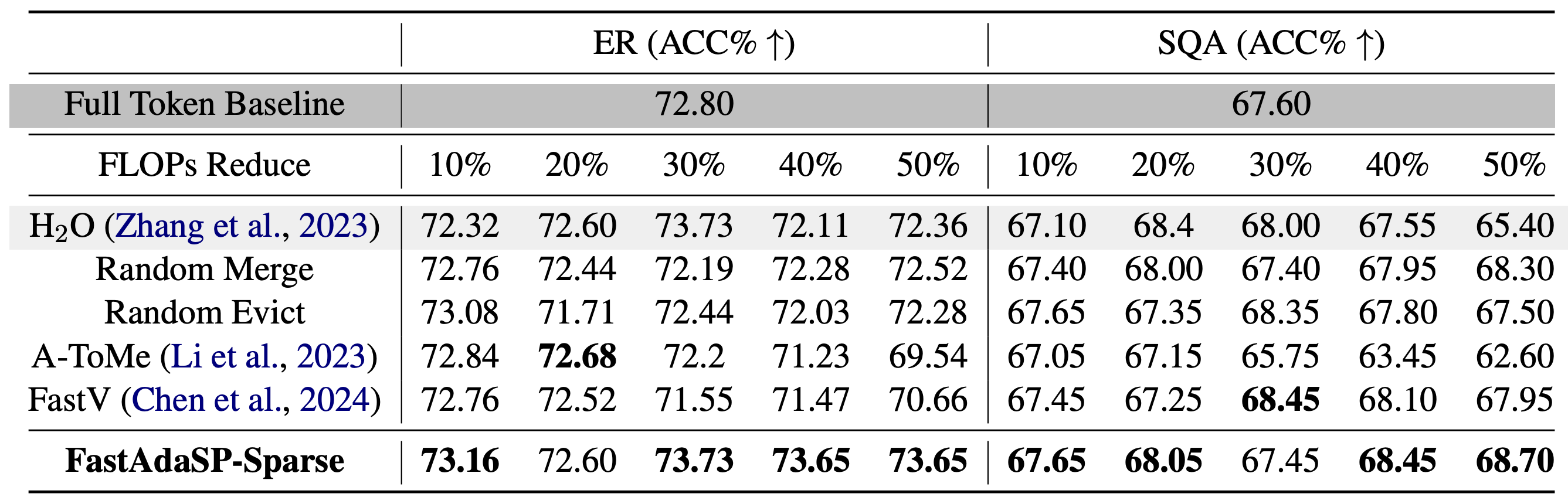
Table 2: Comparison between FastAdaSP with other token reduction methods on WavLLM sparse tasks.
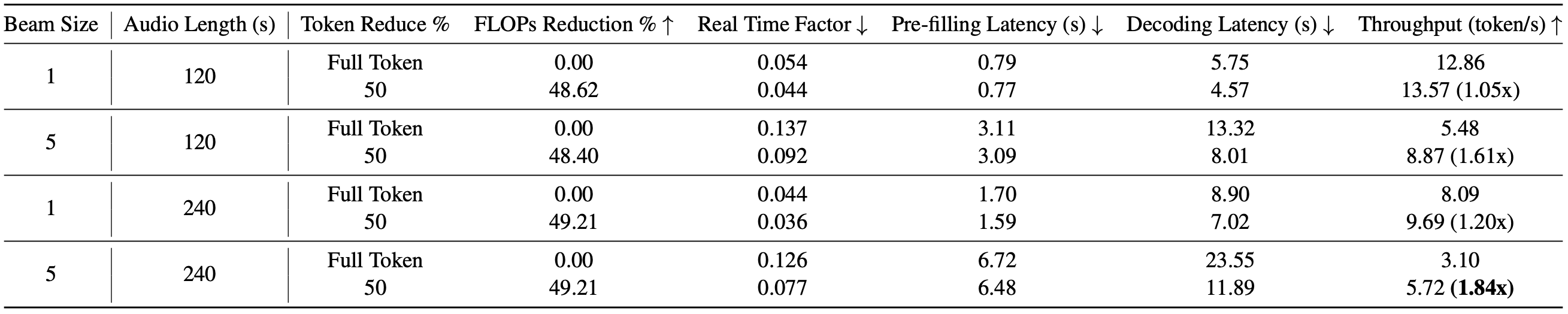
Table 3: Long Sequence Computational cost experiments on A100. Long sequence audio samples (120s and 240s) input on WavLLM using one A100 80GB GPU.
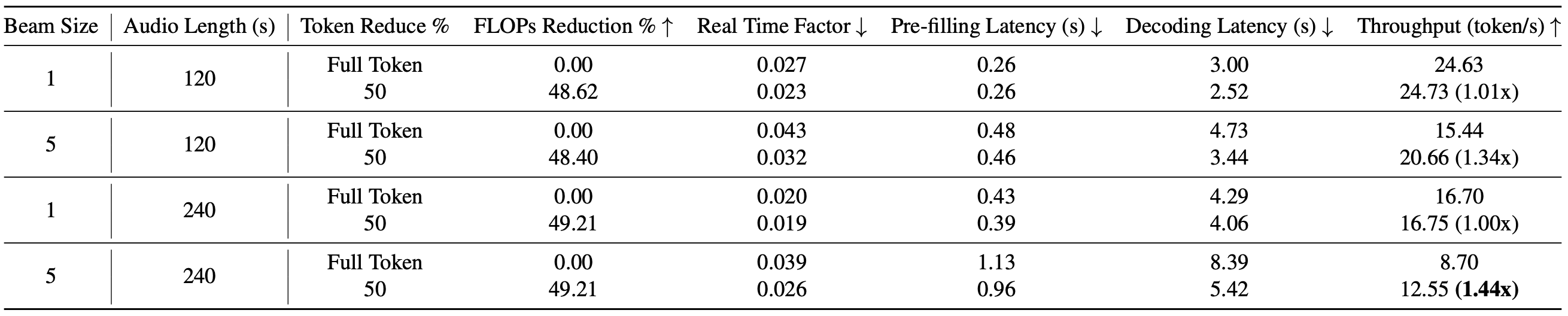
Table 4: Long Sequence Computational cost experiments on H100. Long sequence audio samples (120s and 240s) input on WavLLM using one H100 80GB GPU.
FastAdaSP demonstrates that multitask-adapted efficient inference is achievable in large Speech Language Models without sacrificing performance. By leveraging weighted token merging and adaptive layer selection, FastAdaSP significantly reduces computational complexity while maintaining or even improving task accuracy across various speech-related applications. The framework sets a new standard for efficient model adaptation, making it highly suitable for deployment in resource-constrained environments. Future work will focus on expanding the applicability of FastAdaSP to other modalities such as vision. The next stage of this study is to investigate the unified methodology to accelerate both audio and vision modalities simultaneously in Audio-Visual LLM, which enable more efficient inference for long video understanding.
@article{lu2024fastadasp,
author = {Yichen Lu and Jiaqi Song and Chao-Han Huck Yang and Shinji Watanabe},
title = {FastAdaSP: Multitask-Adapted Efficient Inference for Large Speech Language Model},
journal = {EMNLP},
year = {2024},
}